Coding AgentsJetBrains IDE PluginAutonomous Code RepairAST MergingLLM-as-a-JudgeSWE-bench
From Research Agent to Acquired Product: What I Learned Building the AutoCodeRover IDE Plugin
How I turned an academic code repair agent into a developer tool, built a self-correcting feedback loop, and designed an AST-level patch merge system that Git can't do.
At a Glance
| SWE-bench Verified | 51.6% resolve rate (Jan 2025) |
| Outcome | Acquired by Sonar |
| Published | ISSTA 2024 + arXiv (SpecRover) |
| Timeline | Aug 2024 to May 2025 (10 months) |
| Stack | Kotlin (plugin) · Python (agent backend) · GumTree · JetBrains PSI · OkHttp · SSE |
| My contributions | IDE plugin (end-to-end) · Interactive feedback loop · Self-Fix Agent · AST-level Patch Alignment |
| Where it is today | Sonar Foundation Agent (Feb 2026) · #1 on SWE-bench leaderboard (Feb 2026) |
I was an undergraduate at NUS when I joined the AutoCodeRover team. The system could already resolve real GitHub issues autonomously, combining LLM reasoning with structure-aware code search to localize faults and generate patches. It had just been acquired by Sonar to become the foundation of their remediation platform.
My job was to take something that worked well on benchmarks and make it work for real developers. That meant building an IDE plugin from scratch so developers could use AutoCodeRover without leaving their editor, and making the agent itself smarter when things went wrong.
This post is about the design decisions behind both of those projects, what I learned from each, and why the gap between "works on a benchmark" and "works for a human" is wider than most people think.
The problem with benchmark-only agents
AutoCodeRover resolves GitHub issues through a multi-agent pipeline: a
Context Retrieval Agent searches the codebase via AST-aware APIs and infers intended behavior as natural language specifications, a Patching Agent generates a fix, a Reviewer Agent validates it against a reproducer test, and a Selection Agent picks the best candidate.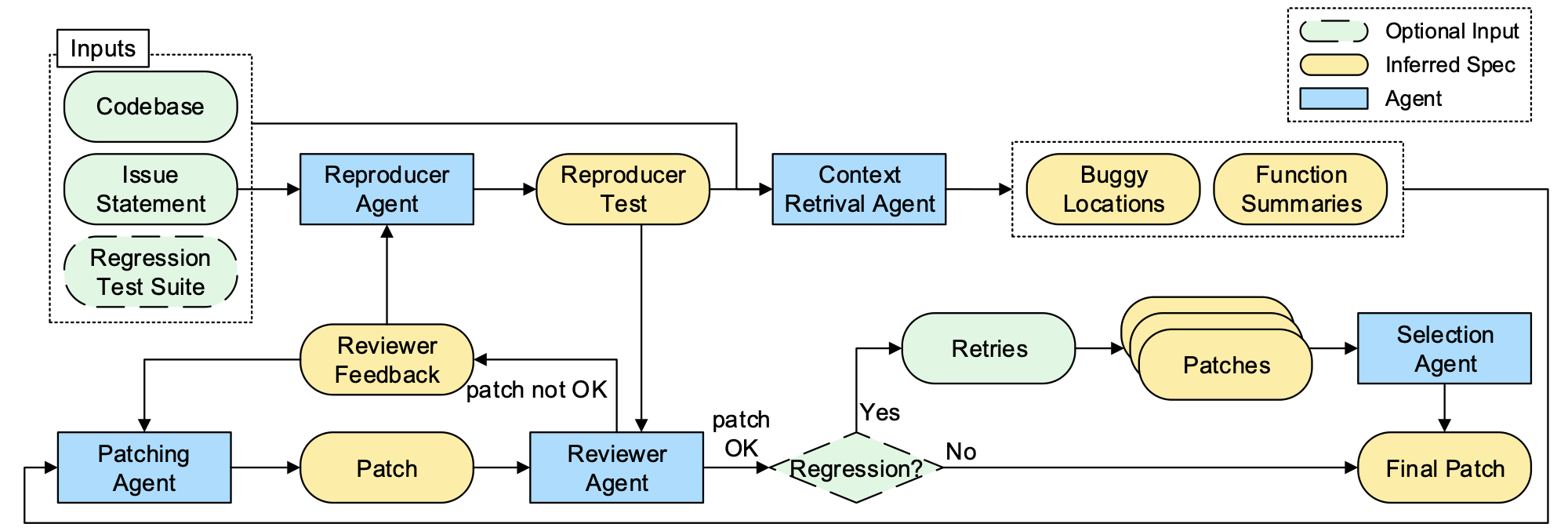 SpecRover pipeline diagram from the research paper
SpecRover pipeline diagram from the research paperOn SWE-bench, this pipeline runs end-to-end with no human involvement. The input is a well-formed GitHub issue. The output is a diff.
Real development looks nothing like this.
A developer working on a project has uncommitted changes. They describe bugs in vague, incomplete sentences. They want to see why the agent made a decision, not just the final diff. They want to say "no, that's the wrong file" and have the agent listen. And they want all of this inside the tool they already use.
Bridging that gap was my entire project.
Building the IDE plugin
I built the AutoCodeRover JetBrains plugin from scratch in Kotlin. It works across IntelliJ IDEA, PyCharm, and other JetBrains IDEs. The core idea is simple: a chat-based tool window embedded in the IDE where developers describe issues in natural language and AutoCodeRover handles the rest.
But "simple" stops at the concept. The implementation required deep integration with IDE internals that most developers never touch.
Context enrichment
A prompt like "fix the broken function call in this file" is useless to a remote agent that has no idea which file "this" refers to. I solved this by automatically enriching every issue description before it reaches the agent. The plugin tracks the developer's last 10 cursor positions using a
CaretListener, records which files are currently open, and uses JetBrains' PSI (Program Structure Interface) to find all references to classes and methods mentioned in the description. If a developer types "the function processData in DataHandler fails on edge cases," the plugin extracts "processData" and "DataHandler," then traverses PSI elements to find every reference with its line number and enclosing context.Without enrichment, the
Context Retrieval Agent often spent multiple rounds retrying searches in large codebases. With enrichment, it had a "search corridor" that pointed it toward the right files on the first attempt.Real-time streaming and agent transparency
The plugin communicates with the AutoCodeRover backend through HTTPS and Server-Sent Events (
SSE). When a developer submits a task, the backend returns a subscribe_link that streams the agent's intermediate reasoning in real time. The plugin maintains this connection using OkHttp and renders each step as a collapsible panel in the chat UI.This transparency turned out to be more important than I expected. Developers did not just want the final patch. They wanted to see the
Context Retrieval Agent's API calls, the Patching Agent's reasoning, and the Reviewer Agent's verdict. Making the agent's thought process visible was essential for trust. If a developer can expand a panel and see that the agent searched the right file and found the right function, they are far more likely to accept the patch.Background listeners
The plugin does not just wait for developers to type a bug report. It actively monitors IDE events. A
BuildProgressListener intercepts build failures, filters out noise, and surfaces the actual errors with a one-click option to send them to AutoCodeRover. A separate listener handles test failures by locating Gradle's HTML test report on disk, parsing it with JSoup to extract the failing class, method, error type, and stack trace, and packaging all of that into a structured prompt.When a build fails or a test breaks, the developer does not have to context-switch at all. The error appears in the chat panel with a button that says "ask ACR to fix this." One click, and the agent has everything it needs.
SonarLint integration
Unlike bugs, code quality issues have well-defined rules and expected fixes, which makes them an ideal target for autonomous remediation: the success rate is high and the risk of a bad fix is low. I embedded the SonarLint Core 10.3.0 analysis engine directly into the plugin for Java and Python. Developers can run static analysis from within the AutoCodeRover panel, see issues grouped by file in an expandable tree, and send individual issues or batched selections to the agent for automated fixes.
This connects two workflows that are normally disconnected: identifying code quality issues and fixing them. SonarLint tells you what is wrong. AutoCodeRover fixes it. The plugin makes that a single step.
Making the agent interactive
The original AutoCodeRover was a single-pass system. You gave it an issue, it ran its pipeline, and it returned a patch. If the patch was wrong, you had to start over from scratch. That is fine for a benchmark. It is terrible for a developer who can see exactly where the agent went wrong and just wants to say "try a different file."
I redesigned the agent backend to support interactive feedback at every stage of the pipeline.
The replay mechanism
The key insight was that feedback at a specific point in the pipeline implies satisfaction with everything before that point. If a developer is giving feedback on the
Patching Agent's output, they are implicitly saying the Context Retrieval Agent did its job. So instead of re-running the entire pipeline, the system reloads the saved intermediate states of preceding agents, re-executes only the targeted agent with the feedback incorporated, and then runs the downstream agents on the new output.
Each agent saves its intermediate
state after execution. States are passed along the pipeline, with each agent extending the state with its own results. When feedback arrives for a specific agent, the system locates the corresponding LLM response by its UUID, discards everything generated after that response, injects the feedback as a transitional prompt, and re-executes from that point.This made the interaction feel like a conversation rather than a slot machine. Developers could provide small, incremental corrections, and each piece of feedback was preserved in a
feedback_history that accumulated across multiple rounds.The Self-Fix Agent
The interactive feedback loop works when a developer is watching. But what about when the agent fails on its own? The original system would just return an inapplicable patch and wait.
I added a
Self-Fix Agent that handles this automatically. When a patch is marked as inapplicable by the Reviewer Agent, the Self-Fix Agent diagnoses what went wrong: it collects the specific failure reasons, then uses a Chain-of-Thought prompt to identify which agent in the pipeline most likely caused the problem. The prompt teaches the LLM about the role of each agent, with special emphasis on the Context Retrieval and Patching Agents since they most directly affect patch quality.Once the faulty agent is identified, the Self-Fix Agent generates targeted corrective feedback and triggers the same replay mechanism I built for interactive feedback, but with the automatically generated feedback instead of human input. This loop repeats up to a predefined retry limit. In practice, the most common failure mode was the
Context Retrieval Agent proposing incorrect buggy locations, which the Self-Fix Agent caught by recognizing that the generated patch referenced code elements that did not exist at the proposed location.
The result is a system that can often recover from its own mistakes without any human involvement. It is the same architectural pattern as the interactive feedback loop, just with the LLM acting as both the critic and the developer.
Patch Alignment: merging code at the AST level
This was the hardest engineering problem in the entire project, and the one I am most proud of.
Here is the scenario: a developer pushes a commit, keeps working locally, and triggers AutoCodeRover to fix a bug. The agent generates a patch based on the latest pushed commit (the baseline). But by the time the patch comes back, the developer's local files have diverged from that baseline. A standard
git apply fails because the context lines do not match.The naive solution is to tell the developer to commit their changes first. But that breaks the whole point of a seamless workflow.
I built a three-way AST merge system using GumTree, a tool that diffs code at the Abstract Syntax Tree level instead of the text level. The key advantage: AST-level merging understands structure. Consider a developer who renames a method parameter from
data to input throughout a function, while ACR simultaneously adds a null-check at the top of the same function. Git sees every line as changed (because the parameter name changed everywhere) and flags the entire method as a conflict. The null-check insertion is lost in the noise. GumTree recognizes that the parameter rename is a node-level update and the null-check is a structural insertion, and merges both cleanly.The algorithm works in three phases.
Phase 1: Prepare three ASTs. The plugin retrieves the baseline code from the latest pushed commit using
JGit, gets the developer's current local file, and applies the ACR patch to the baseline to produce a patched version. All three versions are parsed into ASTs using GumTree's JdtTreeGenerator.Phase 2: Three-way merge. GumTree's
Matcher produces mapping stores for baseline-to-modified and baseline-to-patched. For every node in the baseline AST, the algorithm creates a NodeTriple: (baseline node, matched modified node, matched patched node). The merge decision follows a straightforward priority:| Condition | Result |
|---|---|
| All three nodes match | Keep baseline (no change) |
| Baseline = modified, but patched differs | Accept the patch's change |
| Baseline = patched, but modified differs | Accept the developer's change |
| Modified and patched both changed identically | Accept either (both agree) |
| Modified and patched changed differently | Flag conflict, fall back to baseline |
After processing all baseline triples,
handleExtraNodes handles newly added nodes from both versions by climbing up the parent chain to find a matched ancestor and attaching the new node there.Phase 3: Reconstruct and apply. The merged AST is converted back to source code and written to the editor, with changed lines highlighted so the developer can see exactly what was modified.
This approach eliminates an entire class of false conflicts. A developer and an agent can modify different aspects of the same function, and the merge handles it correctly because it operates on structure, not text. It is something Git fundamentally cannot do.
What I learned
The gap between research and product is a design problem, not a technical one. AutoCodeRover's core algorithm was already strong. The challenge was never "can the agent generate a good patch." It was "can a developer trust and use the patch without leaving their workflow." Transparency (showing the agent's reasoning), interactivity (letting developers correct mistakes mid-run), and seamlessness (background listeners, context enrichment, AST-level merging) were what turned a research tool into a usable product. None of those appear in the SWE-bench score.
Agents need escape hatches. A fully autonomous agent that fails silently is worse than a semi-autonomous agent that asks for help. The interactive feedback loop and the Self-Fix Agent are both escape hatches. One involves a human, the other does not. Both exist because no agent gets it right every time, and the real question is what happens when it does not.
AST-level operations are underused in developer tools. Text-based diffs are a 50-year-old technology. We have much better representations of code now. The Patch Alignment work showed me that operating on the AST instead of raw text eliminates an enormous amount of accidental complexity. I think more developer tools should be built this way.
Where AutoCodeRover is today
After the Sonar acquisition, the AutoCodeRover team built on this foundation to create the Sonar Foundation Agent. In February 2026, it claimed the top spot on the SWE-bench leaderboard with 79.2% on SWE-bench Verified and 52.62% on SWE-bench Full, at an average cost of $1.26 per issue. The team moved from the constrained two-stage workflow I worked on to a single-agent "free workflow" architecture, leveraging thinking models with less prescriptive prompts. The core AST search tools from the original AutoCodeRover are still part of the system.
It is a good reminder that research systems do not stay static. The interactive feedback loop and Self-Fix Agent I built were designed for a world where models needed more guardrails. As models got better, the team gave the agent more autonomy. That is exactly the right evolution, and the architectural patterns (state management, feedback injection, replay mechanisms) carry forward even as the workflow changes.
This project was my undergraduate Final Year Project at the National University of Singapore, supervised by Professor Abhik Roychoudhury. The AutoCodeRover research was published at ISSTA 2024, with the SpecRover extension on arXiv. The system achieved 51.6% on SWE-bench Verified by January 2025 at $0.65 per issue.
I built the JetBrains IDE plugin end-to-end, designed the interactive feedback and replay mechanism, implemented the Self-Fix Agent, and created the GumTree-based Patch Alignment system.
Zanwen (Ryan) Fu is a Software Engineer and MS Computer Science student at Duke University, focused on building production-grade agentic AI systems. He joins Robinhood's Agentic AI team as an MLE intern in May 2026. More at zanwenfu.com.